고정 헤더 영역
상세 컨텐츠
본문
[Elastic Stack] Elasticsearch Index와 Shard 개념
인덱스(Index)와 샤드(Shard)
지난 포스팅에서 Elasticsearch에서 인덱스는 하나의 “논리적인 저장 단위”이고 샤드는 “물리적으로 노드에 저장되는 단위”라고 정의했었다. Elasticsearch나 다른 NoSQL 또는 Kafka와 같은 분산 처리 환경에 익숙하지 않다면 논리적인 저장 단위와 물리적으로 저장하는 단위가 나뉘어져 있다는 개념이 생소할 것이다. 특히 단일 노드로 Standalone 형식으로 테스트를 진행한다면 더더욱 이해가 어려울 수 있다.
하지만 분산 처리를 함으로써 수평 확장(Scale-Out)이 용이해지고 단일 노드의 물리적인 한계를 극복할 수 있다. 또한 처리량을 높여 오히려 퍼포먼스를 향상시킬 수 있을 뿐만 아니라 고가용성(High Availability)을 통한 장애허용(fault tolerance)을 보장할 수 있다. 아래의 설명과 예제를 통해 인덱스와 샤드에 대해 더 자세하게 살펴 보겠다.
프라이머리 샤드(Primary Shard)
샤드는 “프라이머리 샤드(Primary Shard)”와 샤드의 복제본인 “레플리카(Replica)”로 구성할 수 있다. 프라이머리 샤드는 데이터가 나뉘어 지는 단위이며 설정되는 개수에 따라 각 노드에 분산되어 저장된다. 프라이머리 샤드를 여러개 만들어 저장함으로써 분산 처리의 이점을 가져갈 수 있다. 그러나 아무런 설정 없이 인덱스를 생성하면 1개의 프라이머리 샤드가 디폴트로 설정된다. 6.x 버전까지만해도 디폴트로 5개의 프라이머리 샤드가 생성이 되었으나 오버샤딩의 이슈가 있어 7.0 버전부터는 1개의 프라이머리 샤드가 디폴트로 생성이 된다. 따라서 노드 개수가 아무리 많아도 별도로 설정을 변경해주지 않으면 프라이머리 샤드가 1개로 저장되므로 이점을 살릴 수 없다.
또한 인덱스가 생성된 이후에는 프라이머리 샤드의 개수를 변경하는 것이 불가능하다. 따라서 노드의 개수와 프라이머리 샤드의 개수를 잘 고려하여 초기에 설정을 잘 하는 것이 중요하다. 물론, 중간에 노드 개수를 늘리거나 여러 이유로 프라이머리 샤드의 개수를 조정해야 할 수도 있을 것이다. 원칙적으로 인덱스의 프라이머리 샤드 개수를 조정할 수는 없으나 인덱스 관리 정책 또는 리인덱스(re-index) 등과 같은 테크닉적인 방법으로 인덱스와 프라이머리 샤드 개수를 관리할 수는 있다. 이에 대한 내용은 별도의 포스팅에서 다룰 예정이다.
레플리카(Replica)
프라이머리 샤드를 통해 분산 처리를 하여 퍼포먼스의 이점을 가져갈 수 있지만, 노드에 장애가 발생한다면 최악의 경우 데이터가 유실될 수도 있다. 이를 위해 “레플리카”라는 샤드의 복제본을 저장하여 발생할 수 있는 장애에 대한 장애 허용(fault tolerance) 및 고가용성(High Availability)을 보장할 수 있다.
레플리카는 생성된 프라이머리 샤드를 세트 단위로 지정하여 복제본을 저장한다. 예를 들어, 프라이머리 샤드 개수를 3개로 지정하고 레플리카를 1로 지정하면 샤드 3개가 추가로 저장되므로 총 6개의 샤드가 생성되어 저장된다. 이와 관련한 부분은 아래 그림을 통한 예제로 설명하겠다.
흔히 레플리카를 단순한 백업용이라고 생각하기 쉬우나 Elasticsearch에서 검색 또는 집계 등의 읽기 작업을 진행할 때에는 프라이머리 샤드인지 레플리카 샤드인지 구분 없이 읽어오는 작업을 진행하기 때문에 검색 또는 집계의 성능을 높일 수 있다.
그리고 프라이머리 샤드와는 달리 레플리카는 인덱스가 생성된 이후에도 레플리카 개수를 자유롭게 변경할 수 있다. 이를 이용해 운영 중에도 트래픽 증가나 성능 또는 저장 공간에 따른 유연한 변경이 가능하다.
샤드 세팅 예제
위에서 언급했듯이 7.0 버전 이후에는 인덱스 생성 시 디폴트로 프라이머리 샤드 1개, 레플리카 1세트를 생성한다. 테스트를 목적으로 한다면 상관없겠으나 클러스터 환경에서는 Elasticsearch의 장점을 전혀 살리지 못한다. 프라이머리 샤드와 레플리카 세트는 인덱스 생성 전에 미리 세팅을 해줘야 한다. 포맷은 아래와 같이 할 수 있다.
PUT {{index_name}}
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
} number_of_shard 옵션을 통해 프라이머리 샤드의 개수를 지정할 수 있다. 위 예제에는 3개의 프라이머리 샤드를 세팅한다. number_of_replicas 옵션을 통해 레플리카 세트를 지정할 수 있다. 위 예제에는 레플리카 세트가 1이므로 프라이머리 샤드 갯수만큼 3개의 샤드가 더 추가되어 총 6개(프라이머리 샤드 3 + 레플리카 샤드 3)의 샤드가 생긴다. 위와 같은 방법으로 인덱스를 만들 수도 있지만 인덱스 패턴을 통해 인덱스의 샤드를 지정할 수도 있다.
PUT _index_template/{{index_name}}
{
"index_patterns": [
"{{index_name_pattern}}"
],
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}위와 같이 인덱스 패턴을 사용하면 인덱스 이름 규칙에 따라 인덱스가 생성이 될 때 프라이머리 샤드 3개, 레플리카 세트 2개를 만든다. 이 때에는 프라이머리 샤드 갯수 3개의 2개 세트가 생기므로 총 9개(프라이머리 샤드 3 + 레플리카 샤드 6)의 샤드가 생성된다.
샤드 할당 예제
프라이머리 샤드와 레플리카 세트를 지정하더라도 실제로 샤드가 노드에 어떻게 할당되는지에 대해 좀 더 설명이 필요할것 같다. Elasticsearch 노드 3대에 employee라는 인덱스를 생성하는데 프라이머리 샤드는 3개, 레플리카 세트는 2세트로 설정했다고 가정하여 그림을 통해 설명해 보겠다.

Elasticsearch Cluster에 노드가 3대가 준비되어 있고 프라이머리 샤드 3개, 레플리카 세트 2를 설정했다. 이해를 돕기 위해 프라이머리 샤드는 파란색 원 모양으로 표시를 하고, 레플리카 샤드는 세모 모양으로 표시를 했다. 먼저 프라이머리 샤드 3개를 배치하는 과정이다.

실제로는 랜덤으로 프라이머리 샤드 3개가 노드 3개에 각각 배치되겠지만, 지금은 이해를 돕기 위해 순서대로 프라이머리 샤드 0번, 1번, 2번이 각각 노드 1번, 노드 2번, 노드 3번에 할당하는 예제로 준비했다. 위 그림과 같이 실제로도 Elasticsearch는 데이터를 각 노드에 최대한 고르게 저장하려고 하기 때문에 어느 한 노드에 프라이머리 샤드가 몰리지 않고 각 노드에 분배되어 저장이 된다.
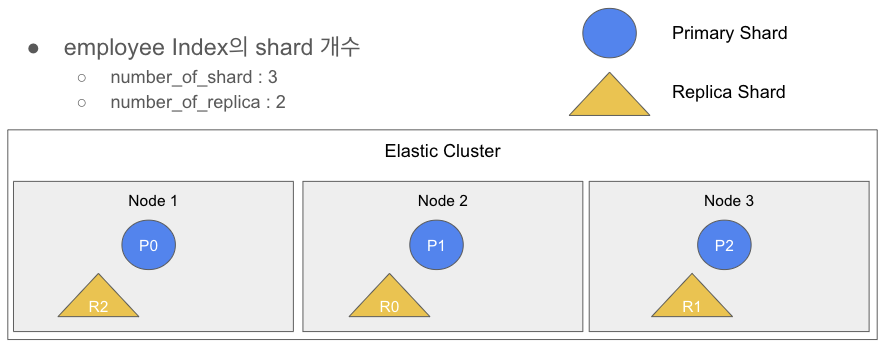
다음은 프라이머리 샤드 3개가 생성된 노드에 레플리카 세트 1개를 할당된 결과이다. 프라이머리 샤드 3개를 그대로 복제 하여 마찬가지로 각 노드에 분배되어 저장이 된다. 하지만 여기서 주목해야할 점이 프라이머리 샤드 0번을 복제한 레플리카 샤드 0번은 노드 2번에, 프라이머리 샤드 1번을 복제한 레플리카 샤드 1번은 노드 3번에, 프라이머리 샤드 2번을 복제한 레플리카 샤드 2번은 노드 1번에 할당이 되었다. 물론 임의로 할당한 것이지만 여기에는 중요한 규칙이 있다. Elasticsearch의 샤드들은 동일 노드에 동일한 샤드가 저장될 수 없다는 점이다. 따라서 노드 1번은 레플리카 샤드 2번 또는 3번만 할당될 수 있다. 임의로 레플리카 샤드 2번을 노드 1에 할당한 다음 노드 2번을 보면 마찬가지로 레플리카 샤드 0번 또는 2번만 할당될 수가 있는데 이미 노드 1번에 레플리카 샤드 2번이 할당되었으므로 레플리카 샤드 0번만 할당된다. 노드 3번은 레플리카 샤드 1번만 남았고, 프라이머리 샤드 1번과 겹치지 않으므로 그대로 할당이 되었다.
이렇게 레플리카 샤드 세트 1개가 할당되는 과정을 살펴보았다. 하지만 number_of_replica 옵션을 2로 설정했으므로 레플리카 샤드 세트 1개가 더 할당되어야 한다. 할당되는 과정은 아래 그림과 같다.
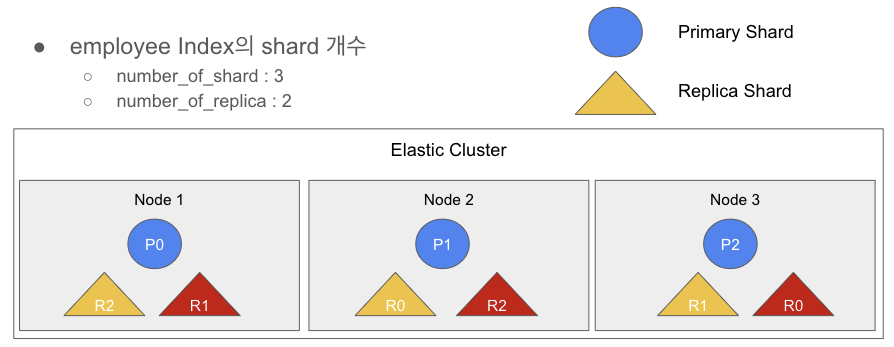
앞서 설명했듯이 Elasticsearch는 동일 노드에 동일한 샤드가 저장될 수 없다. 따라서 노드 1번에는 이미 (프라이머리) 0번 샤드와 (레플리카) 2번 샤드가 할당되어 있으므로 추가로 할당받을 수 있는 샤드는 0번 샤드와 2번 샤드를 제외한 1번 샤드만 가능하다. 따라서 레플리카 샤드 1번이 노드 1번에 할당이 되었다. 마찬가지의 원리로 노드 2번에는 레플리카 샤드 2번, 노드 3번에는 레플리카 샤드 0번이 추가로 할당되었다.
이렇게 프라이머리 샤드와 레플리카 샤드가 노드에 할당되는 과정을 살펴보았다. 하지만 여기서 레플리카 1세트가 더 할당되면 어떻게 될 것인가? 이미 노드별로 할당될 수 있는 샤드 번호가 다 할당되었다. 정답은 아래 그림과 같다.

프라이머리 샤드가 3이고, 레플리카 세트가 3으로 세팅한 결과이다. 프라이머리 샤드 3개와 레플리카 세트 2개는 위에서 설명한대로 할당이 되지만 나머지 레플리카 1세트는 할당되지 않은 상태로 남는다. Elasticsearch에서는 이를 Unassigned Replica 상태로 남긴다. 이러한 인덱스의 상태는 Kibana의 ‘Stack Monitoring’ 탭에서 확인이 가능하다. 아래는 Kibana의 ‘Stack Monitoring’ 탭에서 인덱스 상태 모니터링 화면이다.

세팅한 인덱스의 프라이머리 샤드와 레플리카 샤드가 정상적으로 할당되어 있으면 ‘Green’ 상태, 프라이머리 샤드는 잘 할당이 되었으나 레플리카 샤드가 할당되지 않았다면 ‘Yellow’ 상태, 프라이머리 샤드가 할당되지 않았다면 ‘Red’상태를 나타낸다. 위 화면에서 ‘eployee’ 인덱스는 프라이머리 샤드 1, 레플리카 세트 1을 세팅했으나 단일 노드에서 테스트 했으므로 프라이머리 샤드만 할당이 되고 레플리카 샤드는 할당되지 않았다. 따라서 ‘Yellow’ 상태이다. 나머지 인덱스가 ‘Green’ 상태여도 단 하나의 인덱스가 ‘Yellow’ 상태라면 클러스터 전체의 상태가 ‘Yellow’가 된다. 그러나 성능에는 큰 문제 없이 사용할 수 있으니 너무 걱정하지 않아도 된다.
마무리
이번 포스팅에서는 Elasticsearch의 핵심인 인덱스(Index)와 샤드(Shard)에 대해 실제로 노드에 어떻게 할당이 되는지 살펴보았다. 위에서 설명한 원리를 고려하여 운영 중인 노드 개수에 따라 프라이머리 샤드와 레플리카 샤드를 잘 세팅해주어야 최적화를 통한 좋은 퍼포먼스를 낼 수 있을 것이다. 이번에는 인덱스와 샤드에 대한 간단한 원리만 살펴보았지만 운영에서 더 중요한 부분은 인덱스와 샤드를 '어떻게 관리할 것인가’이다. 굉장히 복잡하고 어려운 주제인 만큼 다른 포스팅을 통하여 자세히 설명해 보겠다.
참고 자료
'Data Platform > Elastic Stack' 카테고리의 다른 글
| [Elastic Stack] Elasticsearch 노드 역할 (0) | 2022.03.27 |
|---|---|
| [Elastic Stack] Filebeat multiple output 에러 (0) | 2022.03.16 |
| [Elastic Stack] Elasticsearch 주요 용어 (0) | 2022.02.24 |
| [Elastic Stack] Elasticsearch 특징 (0) | 2022.02.10 |
| Elastic Stack 이란? (0) | 2022.01.24 |





댓글 영역