고정 헤더 영역
상세 컨텐츠
본문
Elastic Stack이란

출처 : https://www.elastic.co/kr/blog/getting-started-with-elastic-cloud
Elastic Stack이란 Elasticsearch, Logstash, Kibana의 앞글자를 따서 ELK Stack이라고 불리던 기존의 아키텍처에서 Beats 제품군이 추가된 Elastic의 제품군들이다.
보통의 데이터 관련 작업을 수행하게 되면 일반적으로 수집 - 저장/처리 - 분석/시각화 등의 단계를 거치게 된다. Elastic Stack의 그림을 보면 Beats/Logstash - Elasticsearch - Kibana의 순서대로 아래서 위로 올라가게 되는데 Beats/Logstash는 데이터 수집 단계, Elasticsearch는 저장/처리 단계, Kibana는 분석/시각화 단계를 담당하는 제품이다.
Elastic Stack은 각각의 제품군들을 직접 Elastic 다운로드 페이지에서 다운로드 할 수도 있고, SaaS형태로 필요한 만큼의 스펙을 지정하여 deploy된 Elastic Stack을 사용할 수도 있다. 각각은 장단점이 있고 다음 포스팅에서 자세하게 다뤄보겠다.
Elasticsearch란
Elasticsearch는 샤이 배논(Shay Banon)이 개발한 Lucene기반의 검색 엔진이다.
- Lucene에 대한 간략한 소개
- Lucene은 하둡의 창시자인 더그 커팅(Doug Cutting)이 Java 언어로 개발한 오픈 소스 정보 검색 라이브러리이다. 2005년에 Apache Top level의 프로젝트가 되었으며 아파치 소프트웨어 재단에 의해 지원되어 아파치 라이선스 하에 배포된다.
- Lucene은 굉장히 좋은 전문(full-text) 검색 엔진이지만, 라이브러리형태이기 때문에 Lucene을 사용하려면 코드레벨로 라이브러리를 import하여 사용해야 한다. 이 때문에 개발자 이외에는 사용이 어려운 측면이 있다. 또한 확장성을 고려하여 설계되지 않았단 점도 대용량을 다루는 검색 엔진에는 적합하지 않은 점이다.
이러한 이유로 샤이 배논은 분산 처리가 가능하고 다른 프로그래밍 언어들과 쉽게 호환이 가능한 Elasticsearch를 개발했다. 분산 처리가 가능하다는 것은 Scale-out을 통해 Elasticsearch의 노드를 확장할 수가 있다는 점이고, 다른 프로그래밍 언어들과 쉽게 호환이 가능하다는 점은 Elasticsearch가 REST API를 지원하므로 HTTP 통신을 통해 다른 프로그래밍 언어들과 호환한다는 뜻이다. 이 외에도 Elasticsearch는 많은 특징들을 갖고 있지만 Elastic Stack에서의 Elasticsearch를 소개하는 포스팅이니 다른 포스팅에서 Elasticsearch에 대해 더 깊게 다뤄볼 예정이다.
Kibana란
Kibana는 Elastic Stack의 UI를 담당한다. 앞서 Elasticsearch는 REST API를 지원한다고 했으므로 극단적으로는 curl 명령어나 웹 브라우저에서의 호출 또는 Postman으로 활용할 수 있다. 하지만 이렇게 활용하는 것은 매우 불편하고 비효율적이다. Kibana는 dev-tools라는 console을 제공하여 마음껏 쿼리를 날리면서 테스트해볼 수 있다. 또한 분석 및 시각화 툴 답게 여러 그래프를 통해 대시보드를 그릴 수 있으며 대시보드를 만드는 방법은 UI에서 클릭클릭을 통해 만들면 되므로 방법 자체는 매우 쉽다. 키바나 화면은 아래와 같다. (7.16.3 버전)

Logstash란

출처 : https://www.elastic.co/guide/en/logstash/current/introduction.html
Logstash는 데이터 수집과 가공 기능을 제공하는 ETL 툴이다. ETL이란 Extract, Transform, Load의 약자로 글자 그대로 데이터 추출, 변환, 적재를 하는 과정이다. Logstash는 위 그림에서 보듯이 다양한 데이터 소스로부터 데이터를 수집하여 필요에 따라서 변환 작업을 거친 후 다양한 곳으로 데이터를 적재할 수가 있다. Elasticsearch로 데이터를 적재하는 기능만 있는 것은 아니다. Logstash의 좀 더 자세한 구조는 아래와 같다.
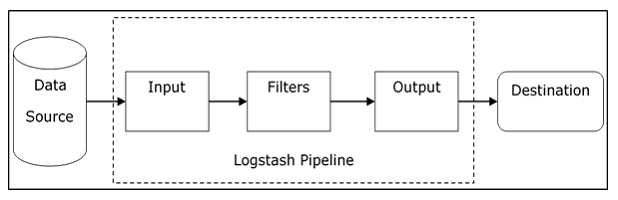
출처 : https://www.tutorialspoint.com/logstash/logstash_internal_architecture.htm
Logstash는 Input plugin, Filter plugin, Output plugin으로 구성되어 있다. 전형적인 ETL 구조이다. Input plugin에서 데이터를 수집할 수 있으며 beats, elasticsearch, s3, jdbc, file 등등 7.16.3 기준으로 굉장히 많은 plugin을 제공하고 있다. 그리고 버전이 올라갈수록 더 많이 제공할 것이다.(실제로 이전 버전에서는 이렇게까지 많지 않았던것 같다.) Filter plugin에서는 csv, json kv처리를 비롯하여 grok pattern 등을 지원하며 왠만한 plugin으로 처리가 될 것이지만 혹시라도 그렇지 못할 경우 ruby plugin을 사용하여 직접 ruby 언어로 코딩할 수가 있다. 굉장히 파워풀하다. Output plugin에서는 elasticsearch, kafka, s3, csv 등등 역시 다양한 plugin을 제공하고 있다. 다른 솔루션들도 마찬가지지만 Logstash의 경우에는 필요에 따라 공식 문서에 원하는 기능이 있는지 확인하며 사용하는 습관을 들이는 것이 좋다.
Beats란

출처 : https://www.elastic.co/guide/en/beats/libbeat/current/beats-reference.html
Beats는 단일 목적의 경량 데이터 수집기이다. 위 그림에서 볼 수 있듯이 Beats는 목적에 따라 크게 Auditbeat, Metricbeat, Filebeat, Packetbeat, Heartbeat, Winlogbeat 등이 있으며 이 외에도 여러 종류의 Beat가 있다. Beats는 Logstash와는 달리 실제 서비스가 동작하는 호스트에 설치를 해야하는 Agent 방식으로 동작하기 때문에 비교적 가볍다고 평가받는 Go 언어로 개발되었다. 또한 Logstash와는 달리 위 그림처럼 Beats는 Elasticsearch에 직접 데이터를 보내거나 Logstash로 데이터를 보낸다. 가벼운 대신 기능은 Logstash보다 부족할 수 있으나 목적에 따라 Beats를 더 파워풀하게 사용할 수도 있다.
마무리
이번 포스팅에서는 Elastic Stack이 무엇인지, 각각의 제품들에는 어떤 것들이 있는지에 대한 간략한 설명을 했다. 사실 각각의 제품들에 대해 다루려면 포스팅 한두개로는 모자랄것 같다. 다음 포스팅에는 Elasticsearch에 대한 더 자세한 포스팅을 할 예정이다.
참고자료
'Data Platform > Elastic Stack' 카테고리의 다른 글
| [Elastic Stack] Filebeat multiple output 에러 (1) | 2022.03.16 |
|---|---|
| [Elastic Stack] Elasticsearch Index와 Shard 개념 (0) | 2022.03.03 |
| [Elastic Stack] Elasticsearch 주요 용어 (0) | 2022.02.24 |
| [Elastic Stack] Elasticsearch 특징 (0) | 2022.02.10 |
| Windows 10에서 Docker Compose로 TLS가 적용된 Elastic Cluster 구성 - 7.16.3 버전 (0) | 2022.01.23 |





댓글 영역